LiteLLM
详细说明
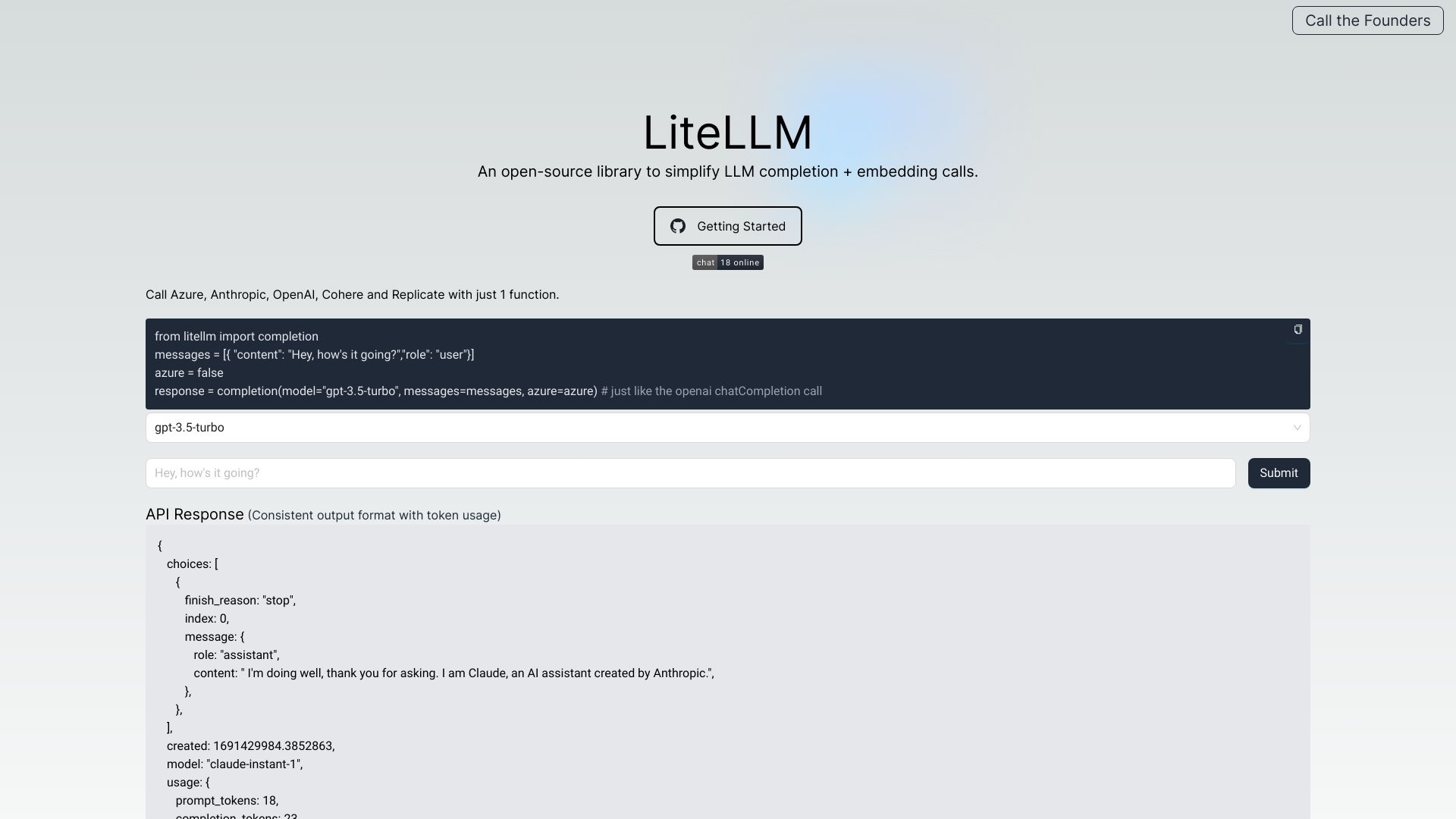
LiteLLM:统一管理和访问100多个LLM的智能网关
功能特性
LiteLLM是一个强大的LLM网关工具,为开发者提供统一接口来管理和访问超过100种大型语言模型。其主要功能特性包括:
- 统一接口:提供符合OpenAI格式的标准化API,简化不同LLM的访问方式
- 多模型支持:兼容GPT、Claude、Llama等100多种主流和新兴LLM
- 智能路由:根据任务类型、成本和性能自动选择最适合的模型
- 负载均衡:智能分配请求到不同的模型提供商,优化资源利用
- 缓存机制:内置智能缓存系统,减少重复请求,提高响应速度
- 成本管理:提供详细的成本分析和预算控制功能,帮助优化使用成本
- 安全保障:支持API密钥管理、访问控制和请求加密,保障数据安全
使用方法
使用LiteLLM非常简单,以下为基本使用步骤:
安装LiteLLM:
bash pip install litellm 基本调用示例:
python from litellm import completion response = completion( model="gpt-3.5-turbo", messages=[ {"role": "user", "content": "请解释什么是量子计算"} ] )
print(response.choices[0].message.content) 切换不同模型:
python 无需修改代码结构,只需更改模型名称
response = completion( model="claude-2", # 切换到Anthropic的Claude模型 messages=[ {"role": "user", "content": "请解释什么是量子计算"} ] ) 应用场景
LiteLLM适用于多种应用场景,为不同需求提供灵活解决方案:
| 应用场景 | 描述 | 优势 |
|---|---|---|
| 企业AI集成 | 在企业系统中集成多种AI能力 | 统一接口,降低维护成本,提高开发效率 |
| 多模型比较 | 评估不同模型在特定任务上的表现 | 一致性测试环境,简化对比流程 |
| 成本优化应用 | 根据任务复杂度动态选择最适合的模型 | 智能路由,平衡性能与成本 |
| 研究与开发 | 快速测试和迭代基于LLM的应用 | 便捷访问多种模型,加速开发周期 |
| 高可用性系统 | 构建具有容错能力的AI应用 | 自动故障转移,确保服务连续性 |
技术特点
LiteLLM的技术架构设计充分考虑了性能、可扩展性和易用性:
标准化适配层:通过将所有模型API转换为OpenAI格式,消除不同模型间的接口差异。
高效异步处理:采用异步I/O和连接池技术,确保高并发场景下的卓越性能。
插件化架构:模块化设计使得添加对新模型的支持变得简单快捷。
智能缓存系统:多层缓存策略,包括内存缓存和持久化缓存,显著降低响应时间和API调用成本。
全面监控体系:提供实时性能指标、错误跟踪和使用统计,便于系统优化和问题排查。
灵活部署选项:支持云端、本地和混合部署模式,满足不同安全和合规要求。
相关问题与解答
问题1:LiteLLM如何处理不同模型提供商之间的API差异?
解答:LiteLLM通过内置的适配器系统处理API差异。每个支持的模型都有对应的适配器,负责参数转换、请求格式化和响应解析。开发者只需使用标准的OpenAI格式调用,LiteLLM会自动将其转换为目标模型所需的格式,并在返回结果时再转换回标准格式。这种抽象层设计使开发者能够轻松在不同模型间切换,而无需深入了解每个模型的特定API细节。
问题2:使用LiteLLM会增加多少延迟?如何优化性能?
解答:LiteLLM经过高度优化,额外延迟通常只占总响应时间的很小部分(一般<5%)。为优化性能,可以采取以下措施:1) 启用LiteLLM的缓存功能,特别是对重复性高的查询;2) 在本地或与用户相近的区域部署LiteLLM实例,减少网络延迟;3) 合理配置连接池大小,根据实际负载调整;4) 使用批量处理接口,减少单次请求开销。对于对性能极其敏感的应用,LiteLLM还提供了轻量级模式,进一步减少处理开销。